Published On Mar 5, 2021
In this video I implement the Vision Transformer from scratch. It is very much a clone of the implementation provided in https://github.com/rwightman/pytorch-.... I focus solely on the architecture and inference and do not talk about training. I discuss all the relevant concepts that the Vision Transformer is using e.g. patch embedding, attention mechanism, layer normalization and many others.
My implementation: https://github.com/jankrepl/mildlyove...
timm implementation: https://github.com/rwightman/pytorch-...
lucidrains implementation: https://github.com/lucidrains/vit-pyt...
00:00 Intro
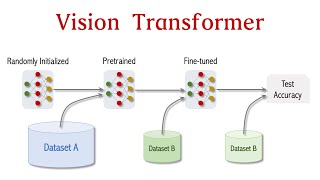
01:20 Architecture overview
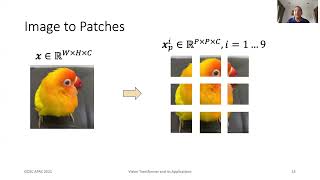
02:53 Patch embedding module
06:39 Attention module
07:22 Dropout overview
08:11 Attention continued 1
10:50 Linear overview
12:10 Attention continued 2
14:35 Multilayer perceptron
16:07 Block module
17:02 LayerNorm overview
19:31 Block continued
20:44 Vision transformer
24:52 Verification
28:01 Cat forward pass
29:10 Outro
If you have any video suggestions or you just wanna chat feel free to join the discord server: / discord
Twitter: / moverfitted
Credits logo animation
Title: Conjungation · Author: Uncle Milk · Source: / unclemilk · License: https://creativecommons.org/licenses/... · Download (9MB): https://auboutdufil.com/?id=600